시간 복잡도는 <문제를 해결하는데 걸린 시간과 입력의 함수 관계>를 의미한다. 보통 빅오 표기법으로 나타낼 수 있다. 시간복잡도는 효율적인 코드로 개선하는데 쓰이는 척도이다. 시간 복잡도가 낮을수록, 효율적인 알고리즘으로, 같은 작업을 하는 코드여도 구현에 따라 성능의 차이가 크게 발생한다.
Big O 표기법: 알고리즘 수행시간은 최악의 경우의 입력에 대한 기본 연산 횟수 수행시간이다. - Big-O 표기 방식 (1)최고 차항만 남긴다. (2)최고 차항 계수(상수)는 생략한다. (3)Big-O(최고차항)로 표기한다.
Big-O (상한접근) : O(n) 최악의 경우 n번까지 수행되면 프로그램을 끝낼 수 있다. f(x)와 g(x) 두 함수가 있을 때 g(x)에 상수 c를 곱한 것이 f(x)보다 큰 경우가 존재하는 지를 확인하는 것. Ex1) 2n + 10 is O(n) → 2n + 10 ≤ cn →(c-2)n ≥ 10 → n ≥ 10/(c-2) →Pick c = 3 and n0= 10 Ex2) n² is not O(n) →n² ≤ cn →n ≤ c → The above inequality cannot be satisfied since c must be a constant.
Big-Omega (하한접근) : 최적의 경우를 n번은 수행되어야 프로그램을 끝낼 수 있다.
Big-Theta (평균접근) : Big-O와 Big-Omega의 평균
시간복잡도 표기 Constatnt time - O(1) 상수 시간: 입력 크기에 상관없이 일정 연산을 수행하는 경우
Primitive Operations - constant amount of time in the RAM model - Basic computations performed by an algorithm - Exact definition is not important EX) Evaluation an expression( 1 + 2 ) Assigning a value to a variable ( x = 2 ) Indexing into an array ( A[3] ) Calling a method & Returning from a method. Not running just calling.
/** Returns the maximum value of a nonempty array of numbers. */
public static doubld arrayMax(double[] data){
int n = data.length; //2 ops (getting data.length, assigning)
double currentMax = data[0]; //2 ops (indexing, assigning)
for(int i=1;i<n;i++){ //2n ops (assigning 1, increasing n-1, comparing n)
if(data[i]>currentMax) //2n-2 ops (comparing 2n-2)
currentMax = data[i]; //0 to 2n-2 ops (depending on 'if', it varies)
}
return currentMax; //1op ( returning)
}
Worst case: 6n+1. Best case: 4n+3
Estimating Running Time a = Time taken by the fastest primitive operation b = Time taken by the slowest primitive operation T(n) is the worst-case runtime of arrayMax. [ a(4n+3) ≤ T(n) ≤ b(6n+1) ] => runtime T(n) is bounded by two linear funcions a와 b는 hardware, software 환경의 constant factor이기 때문에 runtime T(n)은 linear growth rate를 갖는다.
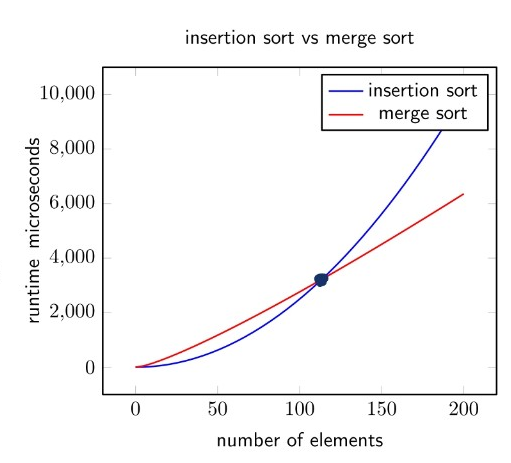
Insertion sort VS merge sort - insertion sort: n²/4, merge sort: 2n log n
- sort a million items? insertion sort takes 70hours, but merge sort takes rougly 40 seconds => The growth rate is not affected by constant factors or lower-order terms!!
Big-O Notation: f(n) is O(g(n)) if there are positive constants c and n0 such that f(n) ≤ cg(n) for n≥n0. 즉, f(x)와 g(x) 두 함수가 있을 때 g(x)에 상수 c를 곱한 것이 f(x)보다 큰 경우가 존재하는지를 확인하는 것. 상한의 개념. Ex1) 2n + 10 is O(n) -> 2n + 10 ≤ cn -> (c-2)n≥ 10 -> n≥ 10/(c-2) ->Pick c = 3 and n0= 10
Ex2) n² is not O(n) -> n² ≤ cn ->n ≤ c -> The above inequality cannot be satisfied since c must be a constant.
- Big-O notation gives an upper bound on the growth rate of a function. "f(n) is O(g(n))"는 g(n)의 growth rate이 항상 f(n)의 growth rate보다 크거나 같다는 것을 의미한다.
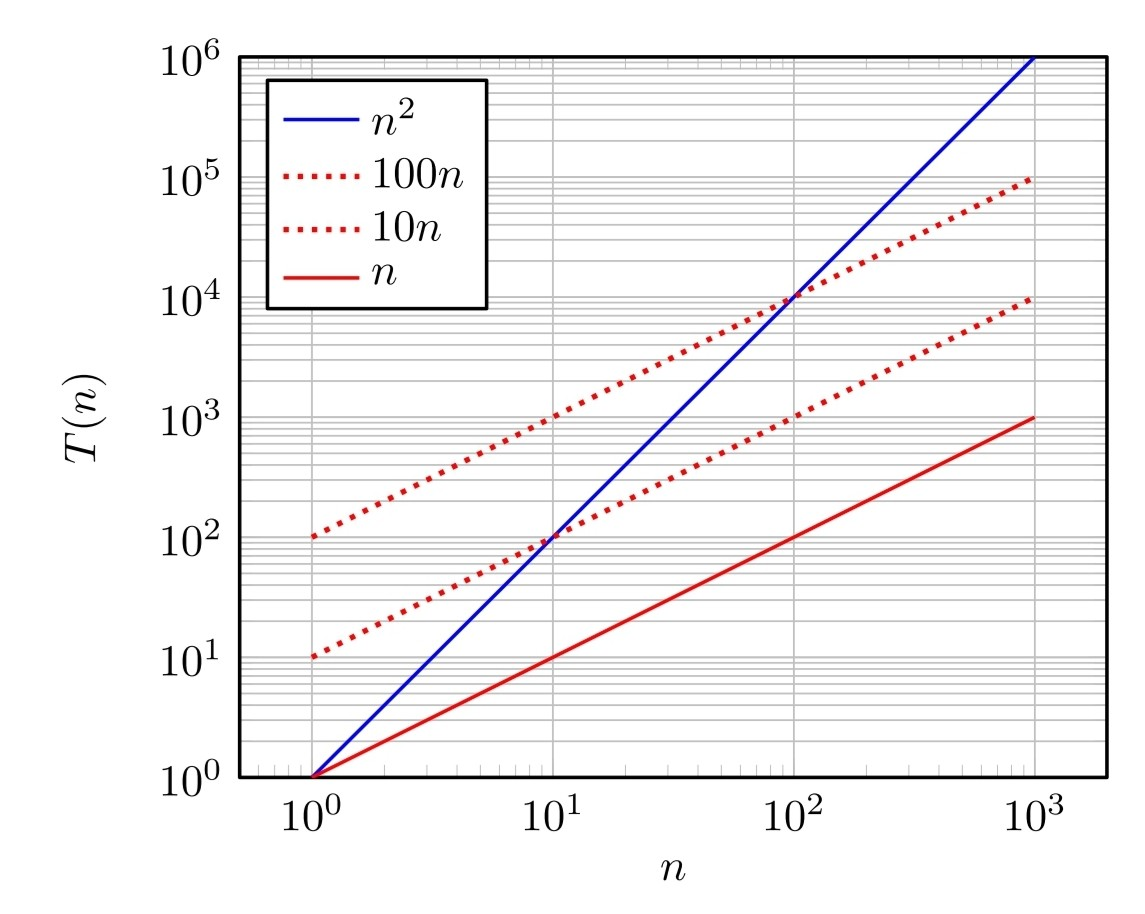
Big-O rules - if f(n) is a polynomial of a degree d, then f(n) is O(n^d) -> Drop lower-order terms -> Drop constant factors - Use the smalles possible class of functions EX) "2n is O(n)" instead of "2n is O(n²)" - Use the simplest expression of the class EX)"3n + 5 is O(n)" instead of "3n+5 is O(3n)"
Asymptotic Algorithm Analysis(점근적 분석): 수가 무한대로 커질 때 함수의 동작을 의미. constant factors나 lower-order terms는 결국 무의미해지기 때문에 primitive operations를 생각할 때 그들을 고려할 필요가 없어진다. - The asymptoti analysis of an algorithm determines the runtime in big-O notation - To perform the asymptotic analysis: (1) Find worst case number of primitive operations excuted as a function of the input size (2) Since constant factors and lower-order terms are eventually dropped, we can disregard them when counting primitive operations.
Prefix average - O(n²)의 경우
/**Return an array a such that, for all i, a[i] equals the average of x[0],...x[i]*/
public static double[] prefixAverage1(double[] x){
int n = x.length;
double[] a = new double[n]; //fill with 0 by default
for(int i=0;i<n;i++)
double total = 0;
for(int j=0;j<=i;j++) //begin computing x[0] + .... + x[i]
total+= x[j];
a[i] = total / (i+1); //record the average
return a;
}
- O(n)의 경우
/** Returns an array a such that, for all i, a[i] equals the average of x[0], ...x[i]*/
public static double[] prefixAverage2(double[] x){
int n = x.length;
double[]a = new double[n]; //filled with 0 by default
double total = 0; //compute the prefix sum as x[0] + x[1] + ....
for(int i=0;i<n;i++){
total +=x[i]; //update the prefix sum to include x[i]
a[i] = total / (i+1); //compute the average based on current sum
}
return a;
}
Relatives of Big-O - Big Omega: f(n) is Ω(g(n)), if there is a constant c>0 and an integer constant n0 ≥ 1 such that f(n)≥cg(n) for n≥n0 함수 f(n)이 g(n)에 상수 c를 곱한 결과보다 큰 값이 존재하는 경우(lower bound) - Big Theta: f(n) is θ(g(n)) if there are constants c'>0 and c''>0 and an integer constant n0 ≥ 1 such that c'g(n)≤ f(n) ≤c''g(n) for n ≥ n0 Big-O와 Big-Ω를 동시에 만족시키는 경우(type bound)
Inductive Proof(귀납법) : 어떤 명제의 기본케이스가 참일때, f(n)이 참이라고 가정하고 f(n+1) 역시 참이면 이 명제는 항상 참이 된다. EX) All horses are the same color - Base case : One horse(n이 1이라고 가정할 때, 해당 그룹의 모든 말은 같은 색이다.) - Inductive step : Assume that n horses are always the same color. what about n+1 horese? n+1의 상황에서 말 한마리를 제외한 n마리의 말은 모두 같은 색이다. 제외한 말을 다시 그룹에 넣고 다른 말을 제외해도 n마리의 말들은 같은 색이다. 그러므로 n+1의 말은 모두 같은 색이다. - if n is 2?(반례) : n이 2라면 a가 검정색, b가 하양색으로 색이 달라도 n+1에서 한마리를 제거했을 때 남은 n그룹 (이 경우엔 한마리)의 말은 같은 색(검정색이거나 하양색)이다. 이러한 경우 n 그룹의 말의 색은 같지만, n+1마리 그룹의 말은 색이 다르다.
Introduction - Data Structure? 자료구조는 컴퓨터가 data를 구조화(organize)하는 효율적인 방법을 의미한다. - Classification by data form
Simple Structure
Primitive data types (integer, real number, character, string)
Linear Structure
1-to-1 relationship between front and rear components (array, list, linked list, stack, queue, deque, ....)
Non-Linear Structure
1-to-N or M-to-N relationship between front and rear components (tree, graph, ....)
File Structure
set of records (sequential file, indexed file, direct file,....)
Data structure VS algorithm - Data Structure: Efficient way of organizing data for computer - Algorithm: Efficient way of solving a problem => for Performance! Efficiency means performance of time(how fast) and space(how small).
Measuring program efficiency - Runtime of a program often grows with the input size. - Calculating average runtime isn't easy. => worst-case runtime - Measuring runtime
long startTime = System.currentTimeMillis();
/*(run the algorithm)*/
long endTime = System.currentTimeMillis();
long elapsed = endTime - startTime;
- Dependency (1) Time consuming (2) Hardware dependency (3) Language dependency (4) Compiler dependency (5) OS dependency (6) Many other dependency ...
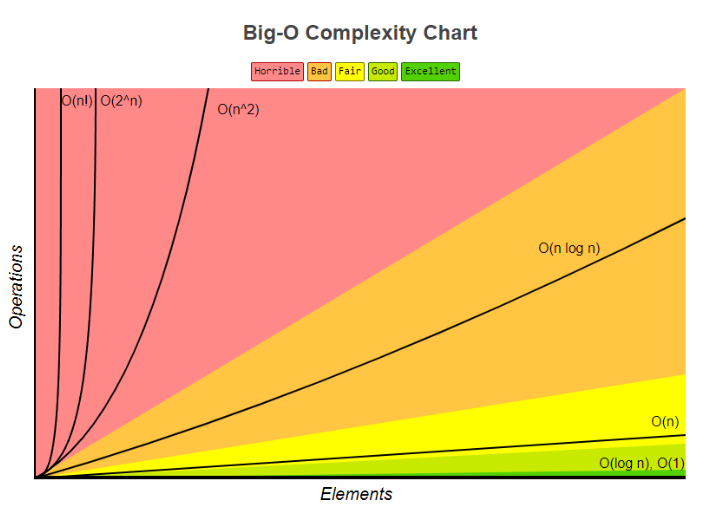
Seven important functions - constant ≈1 - logarithmic ≈ log n - linear ≈ n - N log n ≈ n log n - Quadratic ≈ n² - Cubic ≈ n³ - Exponential ≈ 2ⁿ