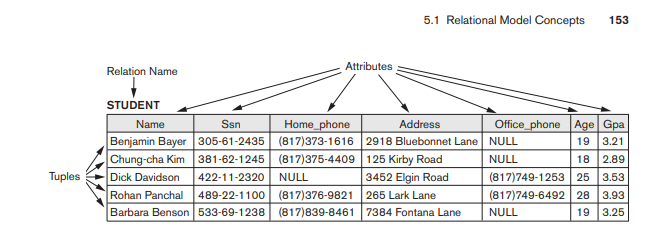
데이터베이스 정규화란?
데이터베이스 정규화는 데이터베이스 설계에서 중복 데이터를 줄이는 것으로, 이를 통해 데이터 무결성을 유지하고 DB저장 용량을 줄일 수 있다. 이를 통해 테이블 구조를 효율적으로 만들고 데이터 삽입 ,삭제,수정 시 발생할 수 있는 이상 현상을 방지한다.
삽입 이상(Insertion Anomaly): 새 데이터를 삽입할 때, 의도치 않은 데이터가 삽입됨으로써 생기는 데이터 불일치
삭제 이상(Deletion Anomaly): 데이터를 삭제할 때 의도치 않은 데이터까지 삭제됨으로써 생기는 데이터의 불일치
갱신이상(Modification Anomaly): 중복된 데이터 중 일부를 갱신할 때 의도치 않은 데이터가 갱신됨으로써 생기는 데이터의 불일치
1. 제 1 정규형(원자성)
모든 열이 원자값(하나의 값)을 가져야 한다. 중첩된 테이블이나 복수의 값을 허용하는 칼럼을 제거한다.

2. 제 2 정규형(부분 함수 종속성 제거)
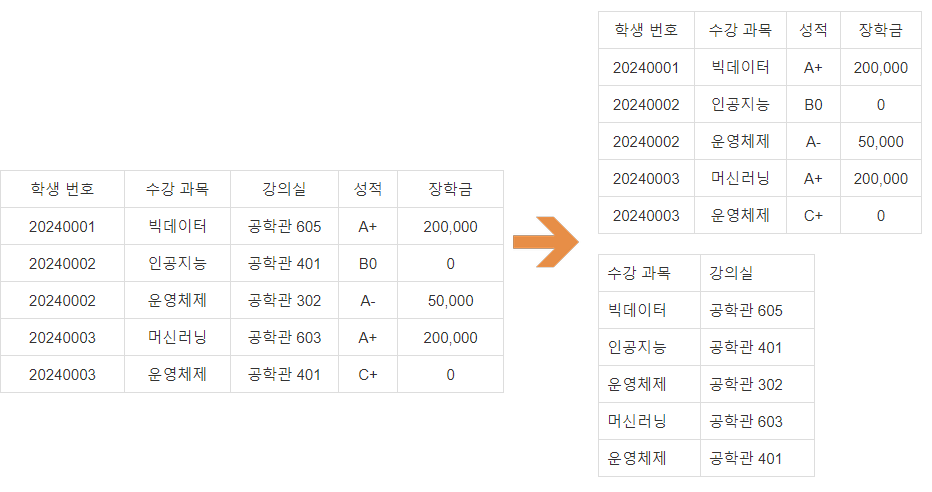
기본 키가 아닌 속성이 기본 키의 부분집합에 종속되지 않도록 한다. 다음 테이블의 기본키는 학생 번호와 수강과목으로 구성되어 있는데, 성적은 두가지 값을 모두 사용해서 값이 정해지지만, 강의실은 강좌이름으로 결정이 되기 때문에 부분 함수 종속성에 해당한다. 따라서 강의실과 강좌이름을 다른 테이블로 분리해야한다. 즉, 기본 키의 일부에만 의존하는 칼럼을 제거하여 부분 함수 종속성을 없앤다.
3. 제 3 정규형(이행적 종속성 제거)
기본키가 아닌 모든 속성이 기본키에만 종속되도록 한다. 기본 키 이외의 다른 속성에 의존하는 칼럼을 제거한다. 이행적 종속이란 A->B, B->C일 때, A->C 인 경우를 의미한다. 한 테이블에서 저런 구조를 가지고 있는 경우를 제거하는 것이 제 3 정규의 목표이다.

4. BCNF(Boyce-Code Normal Form)
모든 결정자가 후보키여야 한다. 즉, 후보키가 아닌 속성은 다른 어떤 속성에도 종속되지 않아야 한다.
후보키란 최소성과 유일성을 만족하는 속성의 집합을 의미한다.
5. 제 4 정규형(다치 종속성 제거)
하나의 테이블에서 여러 독립적인 다치 종속성을 분리한다.
6. 제 5 정규형(조인 종속성 제거)
테이블을 분해하더라도 데이터를 잃지 않고 다시 조인할 수 있어야 한다.
정규화의 장점
1) 중복 데이터 최소화
2) 데이터 무결성 유지
3) 효율적인 쿼리 구조
정규화의 단점
복잡성 증가.
반정규화
데이터베이스 성능 향상을 위해 데이터의 중복을 허용하는 정규화의 반대 의미. 정규화를 통해 종속성과 활용성은 향상되었지만, Join을 많이하고 다량의 범위를 자주 처리해야하는 경우 수행속도가 느려져 반정규화를 수행하기도 한다.
계산 칼럼 추가, 테이블 수직 분할, 테이블 수평 분할, 테이블 병합 등으로 반정규화를 실행할 수 있다.
'CS > 데이터베이스' 카테고리의 다른 글
| [DB]Ch8. SQL-99 Schema Definition, Basic Constraints, and Queries (0) | 2021.11.16 |
|---|---|
| [DB]Ch5. The Relational Data Model and Relational Database Constraints (0) | 2021.10.19 |
| [DB]Ch4. The Enhanced Entity-Relationship(EER) Model (0) | 2021.10.18 |